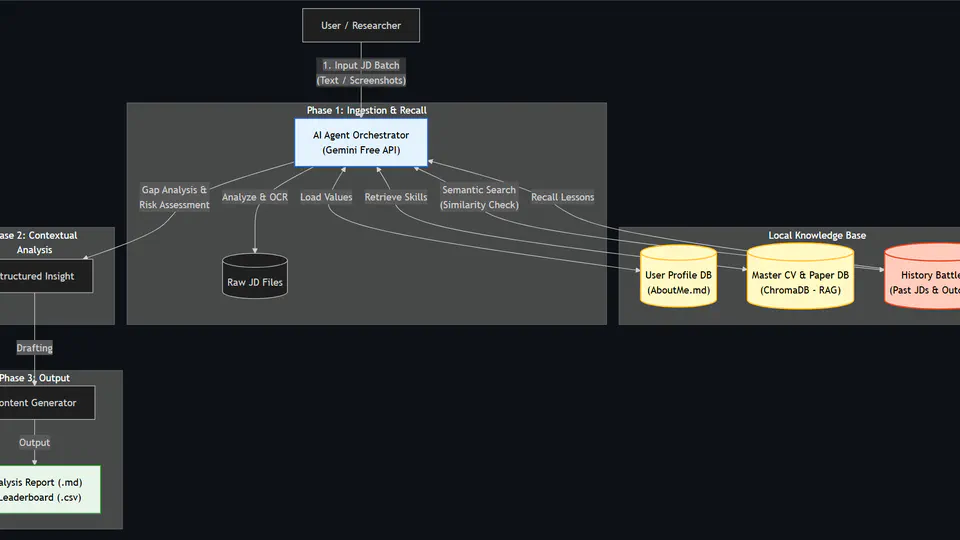
Applied AI Systems
While my Ph.D. trained me to dissect complex problems with academic rigor, my drive for human connection, rooted in my community leadership, inspires me to build tangible solutions.
Since graduating, I bridge these worlds by leveraging Large Language Models (LLMs) and modern AI stacks to rapidly transform ideas into deployed systems. The following projects represent my agile approach to AI engineering: identifying critical daily needs and engineering practical, high-utility solutions that make life safer and easier.

Research Projects
While my applied work prioritizes user-centric utility, it is built upon a foundation of rigorous academic inquiry established during my doctoral and master's studies.
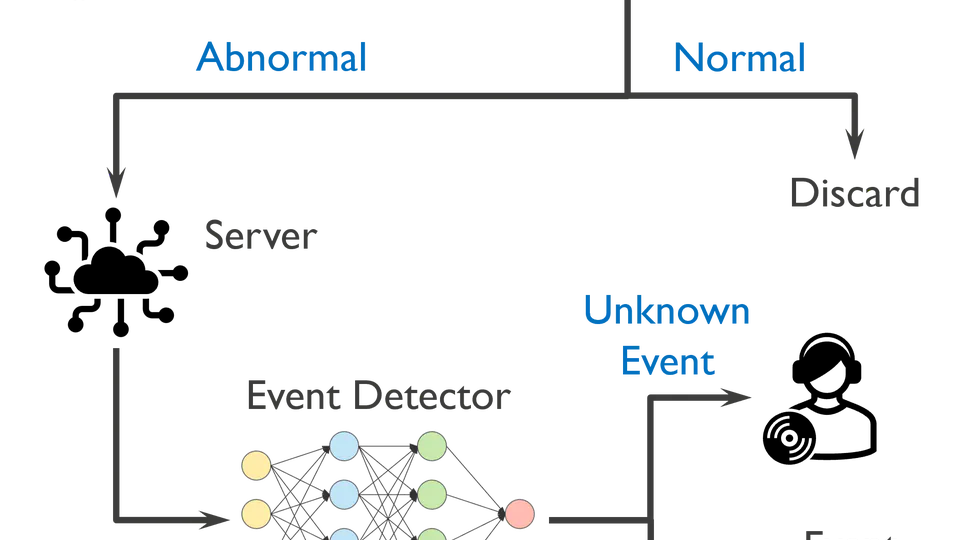
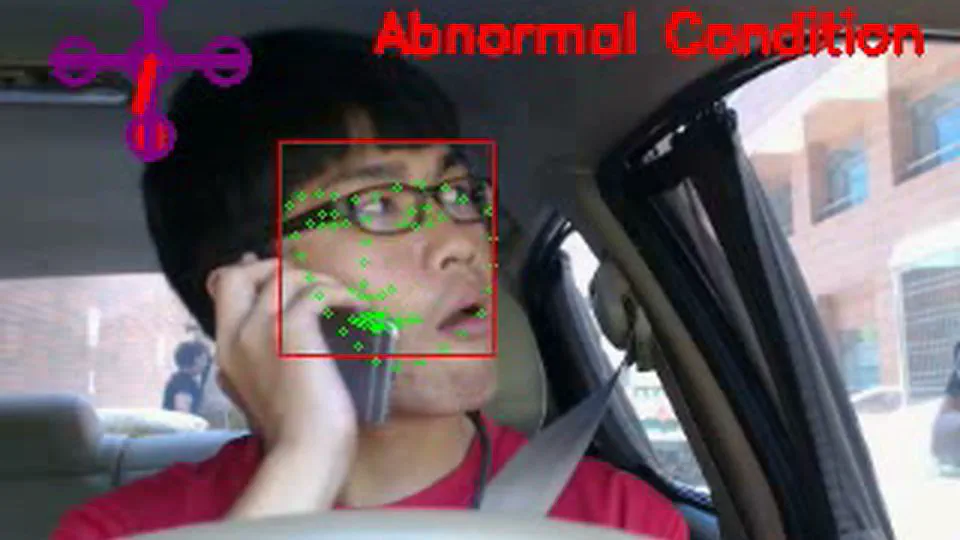
My academic journey at Ghent University and NCKU centered on analyzing real-world data within the fields of surveillance and driver monitoring, with a specific emphasis on audio-visual modalities. I investigated the critical gap between controlled lab environments and unpredictable real-world deployments, proposing novel mechanisms and unsupervised frameworks to bridge this divide. My research spans computer vision, audio processing, and multimodal representation learning, extending into privacy preservation and transferability assessment. This body of work represents my dedication to pushing the boundaries of what AI can perceive without compromising the rights of the people it protects.
My academic journey at Ghent University and NCKU centered on analyzing real-world data within the fields of surveillance and driver monitoring, with a specific emphasis on audio-visual modalities. I investigated the critical gap between controlled lab environments and unpredictable real-world deployments, proposing novel mechanisms and unsupervised frameworks to bridge this divide. My research spans computer vision, audio processing, and multimodal representation learning, extending into privacy preservation and transferability assessment. This body of work represents my dedication to pushing the boundaries of what AI can perceive without compromising the rights of the people it protects.


Research Engineering
"Where theoretical rigor meets production constraints."
This section showcases my work in translating complex research algorithms into robust, deployable systems. Here, the focus is on performance, reliability, and architectural precision.
