
From Lab to Street:Transferable and Privacy-friendly Deep Learning for Urban Surveillance
My PhD dissertation at Ghent University, organized as three method-level directions that share a common deployment setting. The directions emerged from the SenseCity deployment study and address two structural problems revealed there - context drift across sites, and the impossibility of enumerating in advance.
Jun 30, 2025
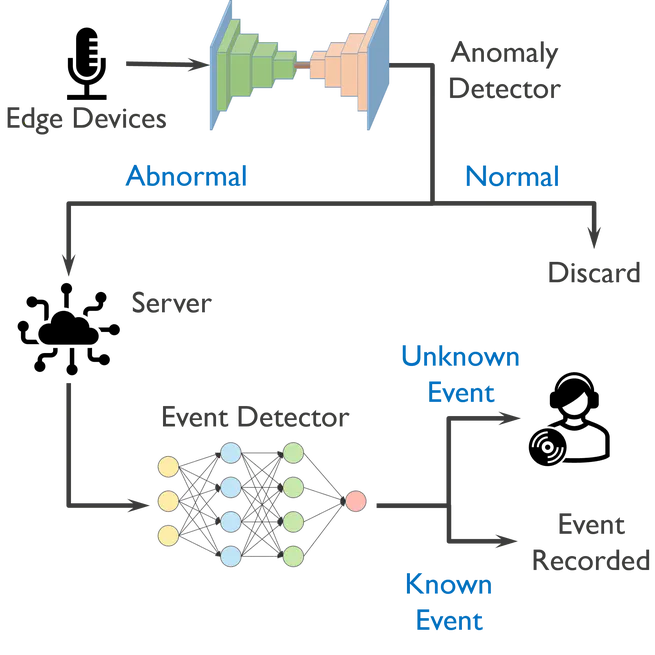
SenseCity: 5000-Hour Real-World Acoustic Surveillance Study
A two-year industrial collaboration with AsaSense, deploying a context-aware acoustic surveillance system across Ghent and Rotterdam at 5000+ hour scale. The study surfaced concrete lab-to-field failure modes that anchored three subsequent PhD research lines.
Jun 30, 2021
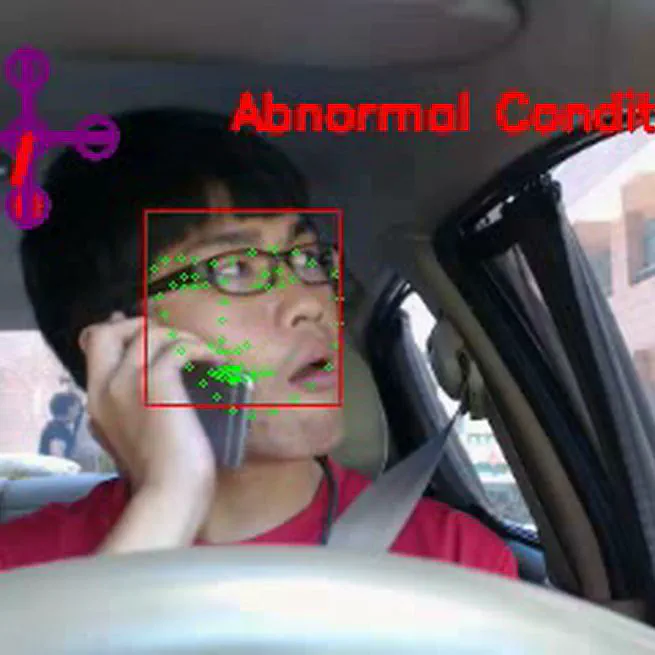
Multimodal Driver Monitoring & Temporal Face Analysis
Multimodal Driver Safety System & Robust Face Analysis A holistic driver monitoring framework developed with ARTC, fusing visual temporal dynamics and ECG signals to enable early anomaly detection and proactive safety intervention. The Research Gap & Motivation From Passive Recording to Proactive Intervention: Standard recognition models often fail in real-world cockpits due to inter-personal variability. A generic model struggles to distinguish between a driver’s natural features (e.g., droopy eyelids) and fatigue. Our Goal: To build a safety-critical system capable of early detection of compromised states by combining non-intrusive visual monitoring with physiological signals (ECG), reducing false alarms and ensuring timely intervention. Operational User Scenario (How it Works) To address the variability mentioned above, the system operates in a three-stage safety loop: Initialization (The “Handshake”): When the driver starts the car, the system silently records a short “calibration sequence” to learn their current appearance (e.g., wearing sunglasses, heavy makeup, or fatigue). This establishes a Personalized Normal Driving Model (PNDM) for the specific trip. Dynamic Monitoring: As the vehicle moves through changing environments (e.g., entering a dark tunnel or facing high-beam glare), the alignment-free visual descriptor maintains robust tracking without being confused by lighting shifts. Proactive Intervention: If the driver shows signs of drowsiness (e.g., prolonged eye closure) AND the ECG sensor detects physiological fatigue, the system triggers a multi-stage alert—first warning the driver, and in critical cases, notifying fleet management or emergency services. Core Methodologies Visual Algorithms: Temporal Coherent Face Descriptor (alignment-free, robust to lighting). System Integration: Multimodal Sensor Fusion (Vision + ECG). Modeling Strategy: Sparse Representation-based Classification with online dictionary learning. Validation: Co-developed and tested with the Automotive Research & Testing Center (ARTC). Technical Architecture & Innovations 1. Personalized Calibration (User-Centric Design) The Problem: Drivers look different every day. Pre-trained generic models fail when users change appearance. The Solution: Implemented a rapid initialization phase that builds a dynamic baseline for each trip. The algorithm detects anomalies based on relative deviation from this baseline, effectively filtering out noise from accessories or facial structure. 2. Robust Temporal Modeling (Visual Subsystem) Alignment-Free: By leveraging temporal consistency across continuous frames, we eliminated the need for fragile face alignment steps, ensuring stability even under rapid head movements. Lighting Invariance: Utilized intensity contrast descriptors to maintain accuracy in challenging lighting conditions (e.g., nighttime driving validated in NCKU-driver database). 3. Proactive Safety Trigger (System Level) Multimodal Logic: Designed the visual module to work in tandem with ECG sensors. While ECG detects physiological drops in alertness, our visual module confirms behavioral lapses (e.g., nodding off). Impact: This cross-verification significantly reduces false positives, ensuring that alerts are only triggered for genuine safety risks. Outcomes & Validation Industry Collaboration: Co-developed with ARTC. Award-Winning: Secured Second Place at the International ICT Innovative Services Awards. Performance: Achieved real-time performance and superior accuracy over state-of-the-art baselines in nighttime scenarios. Resources Publications: Wang Wei-Cheng, Ru-Yun Hsu, Chun-Rong Huang, Li-You Syu (2015). Video gender recognition using temporal coherent face descriptor. IEEE/ACIS SNPD 2015. Chien-Yu Chiou, Wang Wei-Cheng, Shueh-Chou Lu, Chun-Rong Huang, Pau-Choo Chung, Yun-Yang Lai (2019). Driver Monitoring Using Sparse Representation With Part-Based Temporal Face Descriptors. IEEE T-ITS.
Jun 30, 2016

Intelligent Video Analytics & Surveillance Systems
Extracting insights from chaos without labeled data. This research project focuses on the unsupervised understanding of surveillance video, tackling the full pipeline from raw pixel processing to user-centric visualization. The core analysis module leverages background modeling to extract foreground entities, constructing trajectory kinematics descriptors to capture motion patterns. By applying unsupervised clustering on these spatiotemporal features, the system automatically distinguishes between normal routines and anomalous events without requiring manual annotations. Beyond detection, my Master’s thesis addressed the challenge of information presentation. I formulated the dynamic annotation placement as a spatiotemporal optimization problem. By enforcing coherence constraints, the algorithm calculates optimal label positions that maximize readability while minimizing occlusion of critical visual information, ensuring a seamless monitoring experience. (Details and visual results to be followed)
Jun 30, 2016