Embedding-based pair generation for contrastive representation learning in audio-visual surveillance data
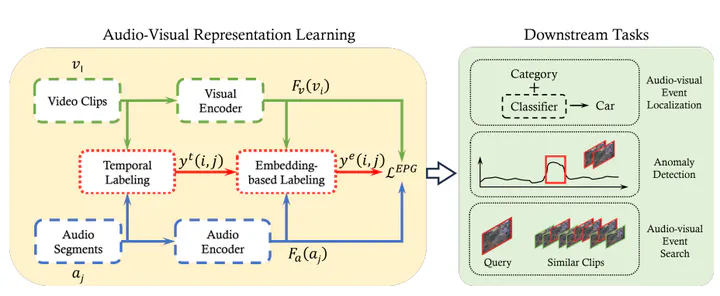
Smart cities deploy various sensors such as microphones and RGB cameras to collect data to improve the safety and comfort of the citizens. As data annotation is expensive, self-supervised methods such as contrastive learning are used to learn audio-visual representations for downstream tasks. Focusing on surveillance data, we investigate two common limitations of audio-visual contrastive learning: false negatives and the minimal sufficient information bottleneck. Irregular, yet frequently recurring events can lead to a considerable number of false-negative pairs and disrupt the model’s training. To tackle this challenge, we propose a novel method for generating contrastive pairs based on the distance between embeddings of different modalities, rather than relying solely on temporal cues. The semantically synchronized pairs can then be used to ease the minimal sufficient information bottleneck along with the new loss function for multiple positives. We experimentally validate our approach on real-world data and show how the learnt representations can be used for different downstream tasks, including audio-visual event localization, anomaly detection, and event search. Our approach reaches similar performance as state-of-the-art modality- and task-specific approaches.
 Conventional contrastive learning methods for self-supervised representation learning rely on an overly strict temporal alignment to generate positive pairs. This approach, while effective in some domains, creates critical issues when applied to continuous surveillance data. The first problem is the prevalence of False Negatives; semantically identical events, such as a car passing, that occur at different times are incorrectly treated as negative pairs, which fundamentally misguides the learning objective and degrades the quality of the learned representations. This leads to a second issue, an Information Bottleneck, where the model learns superficial temporal cues instead of rich, generalizable semantic features, thus limiting its effectiveness on diverse downstream tasks that demand a deeper understanding of the data.
Conventional contrastive learning methods for self-supervised representation learning rely on an overly strict temporal alignment to generate positive pairs. This approach, while effective in some domains, creates critical issues when applied to continuous surveillance data. The first problem is the prevalence of False Negatives; semantically identical events, such as a car passing, that occur at different times are incorrectly treated as negative pairs, which fundamentally misguides the learning objective and degrades the quality of the learned representations. This leads to a second issue, an Information Bottleneck, where the model learns superficial temporal cues instead of rich, generalizable semantic features, thus limiting its effectiveness on diverse downstream tasks that demand a deeper understanding of the data.
To resolve these challenges, we developed a novel self-supervised framework centered on a new mechanism termed Embedding-based Pair Generation. Instead of relying on timestamps, EPG strategically leverages the frequent recurrence of events by sampling positive pairs based on their mutual proximity within the learnt embedding space. This process was coupled with a modified contrastive loss function specifically designed to effectively incorporate these multi-positive pairs, thereby enriching the learning signal and breaking through the information bottleneck.
The results confirmed the superiority of this method. The EPG-trained representations significantly outperformed existing baselines, achieving a 10% performance increase in the task of audio-visual event localization. The efficacy and generality of these features were further validated across a range of applications, including unsupervised anomaly detection and event search. These findings empirically prove that the EPG framework successfully resolves the false negative problem and learns robust, versatile representations from complex, unlabeled surveillance streams in real-world scenarios.