Agentic Career Orchestrator - Multi-Agent LLM System for Strategic Job Triage & Advisory
Agentic Career Orchestrator: Multi-Agent LLM System for Strategic Job Triage & Advisory
An ROI-driven, local-first AI ecosystem designed to augment human judgment through semantic filtering and strategic advisory in high-noise job markets, while preserving data sovereignty.
Current Status: v2 Stable Release (Jan 2026) – full 5‑phase multi‑agent pipeline operational; ongoing prompt refinement, no major architecture changes planned.
Motivation Job hunting as a Ph.D. graduate is fundamentally a semantic search problem disguised as a volume game. The core friction lies in the extremely low signal-to-noise ratio inherent in modern recruitment platforms.
After defending my doctoral thesis, I found myself navigating a market where a single “Machine Learning Engineer” posting could mean anything from data pipeline maintenance to cutting-edge research implementation. Traditional keyword-based searches fail spectacularly: they cannot capture nuances like visa sponsorship policies, distinguish between “nice-to-have” and “required” qualifications, or recognize that my background in audio-visual surveillance directly transfers to anomaly detection in fintech.
The real challenge, therefore, isn’t just about finding jobs: it’s about verification and strategic triage. Manually reviewing hundreds of listings to validate market salaries or check research alignment is exhausting and error-prone. I needed more than a search engine; I needed an ROI-driven intelligent assistant that understands context to filter out the noise, allowing me to allocate my limited cognitive bandwidth exclusively to high-leverage opportunities.
Impact & Core Philosophy Since deployment, this system has transformed job hunting from a chaotic volume game into a disciplined strategic campaign.
Compressed Time-to-Decision: By automating the Observe-Orient-Decide-Act of job filtering, it reduces complex risk assessment from days to…less days, allowing me to focus bandwidth exclusively on high-leverage opportunities. Deep Semantic Qualification: Moving beyond rigid keyword matching, the system evaluates contextual fit: automatically distinguishing between generic “Machine Learning Engineering” roles and research-oriented positions that truly align with my Ph.D. expertise. Uncovered Asymmetric Opportunities: By aggregating independent assessments from the a Multi-Agent Council, the system synthesizes non-obvious connections, such as bridging my audio-visual surveillance background to fintech anomaly detection, that rigid keyword filters typically discard. The core philosophy is unyielding: to build a system that empowers executive decision-making, not replaces it.
I develop this ecosystem not to automatically generate resumes or cover letters for mass applying, but as a specialized analyst team to reduce the burden from repetitive but non-productive works. My aim is by defining the strategic criteria and delegating the ground-level research to the agents, the analyst team handle the preliminary debates and data crunching. This structure allows me to step back from the “grunt work” and focus entirely on the final strategic call, ensuring that every application is tailored with authentic human intuition but backed by machine-speed intelligence.
Research Context: The Dual Purpose Beyond its immediate utility, this project serves as a Proof of Concept for integrating system-level engineering into the academic research workflow.
Although my core research lies in deep learning rather than system engineering, my past works urge me to think my research from a bigger picture. Consequently, importing robust engineering tooling into the research loop seems to be an effective strategy to accelerate the Proof-of-Concept cycle. By validating the Mixture-of-Advisors framework here, this project explores how we can leverage “system thinking” to orchestrate complex models (like video generators and LoRAs) as distinct agents. This project serves as an architectural pilot for physically‑aware synthetic surveillance data generation, validating the Mixture‑of‑Advisors orchestration pattern before applying it to video generators and task‑specific LoRAs.
Beyond its immediate utility, this project serves as a PoC for integrating system-level engineering into the academic research workflow.
System Evolution: From Linear Script to Dynamic Orchestration While the core objective remains unchanged (identifying high-fit opportunities from a sea of noise) the architectural approach has fundamentally shifted from a rigid linear protocol to a dynamic resource orchestration.
v1: Linear Execution (Legacy) v1 operated as a single monolithic script that enforced a “One-Size-Fits-All” protocol. Every Job Description, regardless of its domain (Academic, Startup, Big Tech), was forced through the exact same processing sequence (Step A → B → C).
Rigid Protocol: The system lacked the autonomy to deviate. It applied the same generic analysis prompts to a “Research Scientist” role as it did to a “Backend Engineer” role. Resource Inefficiency: It could not dynamically allocate resources: wasting tokens on irrelevant checks while missing domain-specific nuances that required deeper investigation. v1 was a static procedure: it executed steps blindly, focusing on process completion rather than strategic adaptability.
v2: Adaptive Resource Orchestration v2 refactors the system into a flexible multi-agent ecosystem. Instead of a fixed linear path, it employs a Router Agent to analyze the context of each JD and dynamically “spin up” the necessary agents, allocating computational resources only where they yield the highest ROI.
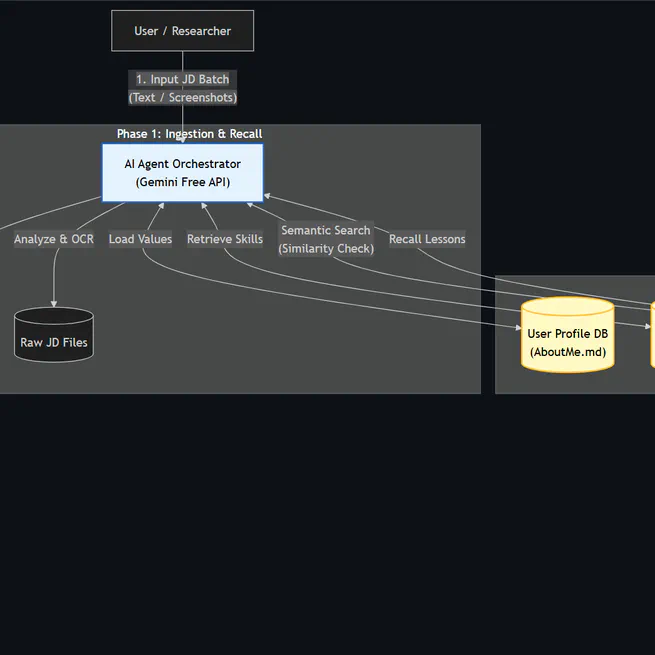
Phase 1: Observation (Tool-Augmented Grounding) Before analysis begins, the system proactively invokes external tools (Salary APIs, arXiv retrieval) to ground the JD in reality, ensuring subsequent agents operate on verified data rather than assumptions.
Phase 2: Orientation (Gatekeeping) A lightweight Triage Agent performs a rapid “Survival Check.” It instantly discards non-viable roles (Visa/Language constraints) before expensive reasoning agents are instantiated, optimizing the computational budget.
Phase 3: Decision (Context-Aware Council) This is the core architectural shift. The system dynamically assembles a Council of Advisors specific to the role.
For a Research Scientist Role: It spins up the 🔬 Academic Reviewer, assessing the domain gap between my research and the target field. For an Early-Stage Founding Engineer: It activates the 🚀 Startup Veteran (analyzing equity potential & risk) and 🏗️ System Architect (assessing scalability requirements). The Technical Advantage: By creating specialized agents, we ensure Context Isolation. This prevents “Context Pollution”, where an LLM gets confused by irrelevant information (e.g., applying corporate HR standards to a scrappy startup role). Each agent sees only what it needs to see, ensuring the signal remains pure. Phase 4 – Strategy War Room (Clustering & ROI) The system steps back from single JDs and enters a war‑room view across all dossiers. It clusters opportunities by similarity patterns (domain, seniority, tech stack, narrative angle) and estimates the ROI of working on each cluster, producing a ranked “battle plan” that prioritizes where limited effort should be invested first.
Phase 5 – Briefing & War Room Editor Finally, a briefing agent synthesizes per‑cluster guidance into concise strategy briefs, while the war‑room editor generates structured tables and bullet‑level action items instead of full ghostwritten documents. It suggests narrative angles, surfaces reusable experience blocks, and prepares checklists of edits so that I stay in control of the final wording while the system handles the pattern‑matching and retrieval work.
The evolution mirrors the transition from a hard‑coded script to an intelligent orchestrator:
v1 was process‑centric (“run every file through these 3 steps”), whereas v2 is resource‑centric (“analyze the target, deploy the right agents, and synthesize the strategy”).
The Architectural Shift The evolution mirrors the transition from a Hard-coded Script to an Intelligent Orchestrator:
v1 Approach: Process-Centric. “Run every file through these 3 steps.” v2 Approach: Resource-Centric. “Analyze the target, deploy the right agents, and synthesize the strategy.” By moving from linear execution to dynamic orchestration, v2 ensures that every decision is backed by the right experts, adapting the system’s behavior to the chaos of the real-world market.
Tech Stack LLM & Orchestration: Python 3.11, Google Generative AI SDK (Gemini API), semantic routing via a Smart Model Gateway. Models: Gemma‑3‑27b‑it for logic & extraction; Gemini‑2.5‑Flash for long‑context strategic synthesis. Memory & RAG: ChromaDB (all-MiniLM-L6-v2), Recursive Character Splitting, JSON/Markdown Serialization Infrastructure: Docker Compose, .env‑based local path binding, local‑first storage of CVs and history. Technical Architecture & Implementation System Architecture Overview The v2 system implements a multi-phase, multi-agent orchestration pipeline with clear separation of concerns. Unlike monolithic single-script approaches, each phase is encapsulated as an independent module with dedicated agents, enabling modular development and targeted optimization.
Core Design Principles:
Phase-Based Pipeline: Five sequential phases (Intel → Triage → Council → War Room → Briefing) with explicit data contracts between stages. Hybrid Model Gateway: A cost-aware routing layer that intelligently switches between quota-friendly models (Gemma) for extraction/filtering and high-capacity models (Gemini Flash) for deep reasoning. Structured Knowledge Layer: A local vector database designed for the semantic retrieval of reusable CV sections per JD. Implementation Stack Core Infrastructure: Python 3.11, Google Generative AI SDK, Docker Compose. Structured Output: Enforced JSON schemas ensure reliable agent communication and metadata parsing. Hybrid Inference Layer: The Workhorse (Gemma 3-27B-it): Handles ~90% of the workload, including JD parsing, keyword extraction, triage filtering, and initial gap analysis. Chosen for its high Rate-Limit (RPD) and efficiency. The Heavy Lifter (Gemini 2.5 Flash): Activated only for tasks requiring massive context windows or deep reasoning, such as deep RAG retrieval and strategic synthesis. Smart Gateway: A router that selects the appropriate model based on task complexity and real-time daily quota availability. Memory & Knowledge: Vector Store: ChromaDB with MiniLM embeddings. Indexing: Personal CV, academic papers, and historical applications. Purpose: Enables the system to retrieve relevant experience blocks and reusable resume snippets for each specific JD. Multi-Agent Architecture The system executes a structured workflow to ensure comprehensive coverage:
Phase 1: Intelligence Gathering (The Scout) Parses raw JDs (with text extraction caching) and invokes external tools (e.g., arXiv API for research group validation, Mock Salary Validator).
Output: An Enriched Dossier containing external context (team credibility, market salary band).
Phase 2: Triage & Gatekeeping (The Gatekeeper) Enforces hard constraints (Visa, PhD relevance, Salary floor).
Output: A structured triage decision. Only “playable” JDs proceed to the Council, saving compute resources.
Phase 3: Mixture-of-Advisors (The Council) Router Agent: Dynamically selects multiple advisors within relevant field per JD (e.g., Academic Analyst and Leadership for senior research roles).
Context Isolation: Each advisor has a dedicated persona definition and memory state, preventing context pollution.
Output: Per-advisor scores and rationales stored in dossier metadata for downstream aggregation.
Phase 4: Strategy War Room (Clustering & ROI) In Phase 4, the system steps back from single JDs and enters a War Room view across all dossiers. Instead of treating each role as an isolated decision, it clusters opportunities by similarity patterns (domain, seniority, tech stack, narrative angle) and estimates the ROI of working on each cluster. For each cluster, the War Room agent looks at:
Rewrite effort: how much real editing is needed beyond a 5‑minute tweak. Reusability: whether a single narrative rewrite can unlock multiple similar roles. Strategic leverage: whether this cluster advances my long‑term trajectory (e.g., research scientist track vs. generic MLE). The output of Phase 4 is a ranked “battle plan”: a prioritized queue of clusters with concrete reasons for why they deserve attention now versus later.
Phase 5: Briefing & War Room Editor Phase 5 turns strategy into execution support rather than a ghostwriter. The Briefing agent synthesizes per‑cluster guidance into a concise strategy brief: which project angles to foreground, which gaps to acknowledge, and which phrasing patterns are reusable across roles.
Instead of generating full resumes or cover letters, the War Room Editor produces structured tables and bullet‑level action items that I can copy into my own documents as needed. It surfaces:
Suggested narrative angles per cluster and per JD (e.g., for Job A, frame my audio‑visual surveillance work as a privacy‑preserving mechanism; for Job B, emphasize high‑throughput anomaly detection). Phrases and experience blocks retrieved from my CV/history that are safe to reuse. A short checklist of edits for each application (what to add, what to cut, what to reframe). This keeps the human firmly in control of the final wording while letting the system handle the tedious pattern‑matching and retrieval work.
Cost & Efficiency Optimization The architecture is strictly ROI-Driven, prioritizing resource allocation to minimize waste:
Aggressive Caching: JD text extraction and intermediate reasoning steps are cached locally to avoid redundant API calls. History Reusability: The RAG module is designed to retrieve reusable sentences from past successful applications, reducing the manual effort in rewriting the same sentence over and over again. Resources System Architecture Diagram GitHub Repository Analysis Sample - Example of Analysis Report of a Fake JD.
Jan 21, 2026