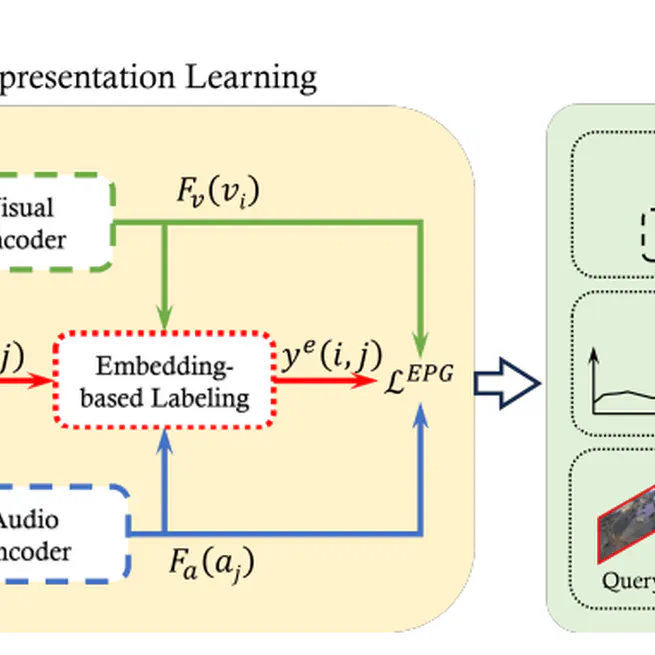
Embedding-based pair generation for contrastive representation learning in audio-visual surveillance data
To address the challenges of false negatives and information bottlenecks in audio-visual contrastive learning for smart city surveillance, this work proposes a novel method that generates semantically synchronized pairs via cross-modal embedding distance, yielding general-purposes representations that achieve competitive performance on multiple downstream tasks.
Jan 13, 2025